六个模型摆在眼前,我停了一下
码艺轩|关于 Perplexity Pro 模型选择的一次认真梳理

这个界面我见过不止一次了。Sonar、GPT-5.4、Gemini 3.1 Pro、Claude Sonnet 4.6、Nemotron 3 Super,还有最上面那个"最佳——选择可用的最佳模型"。每次我都随手点了"最佳",然后继续问我的问题。
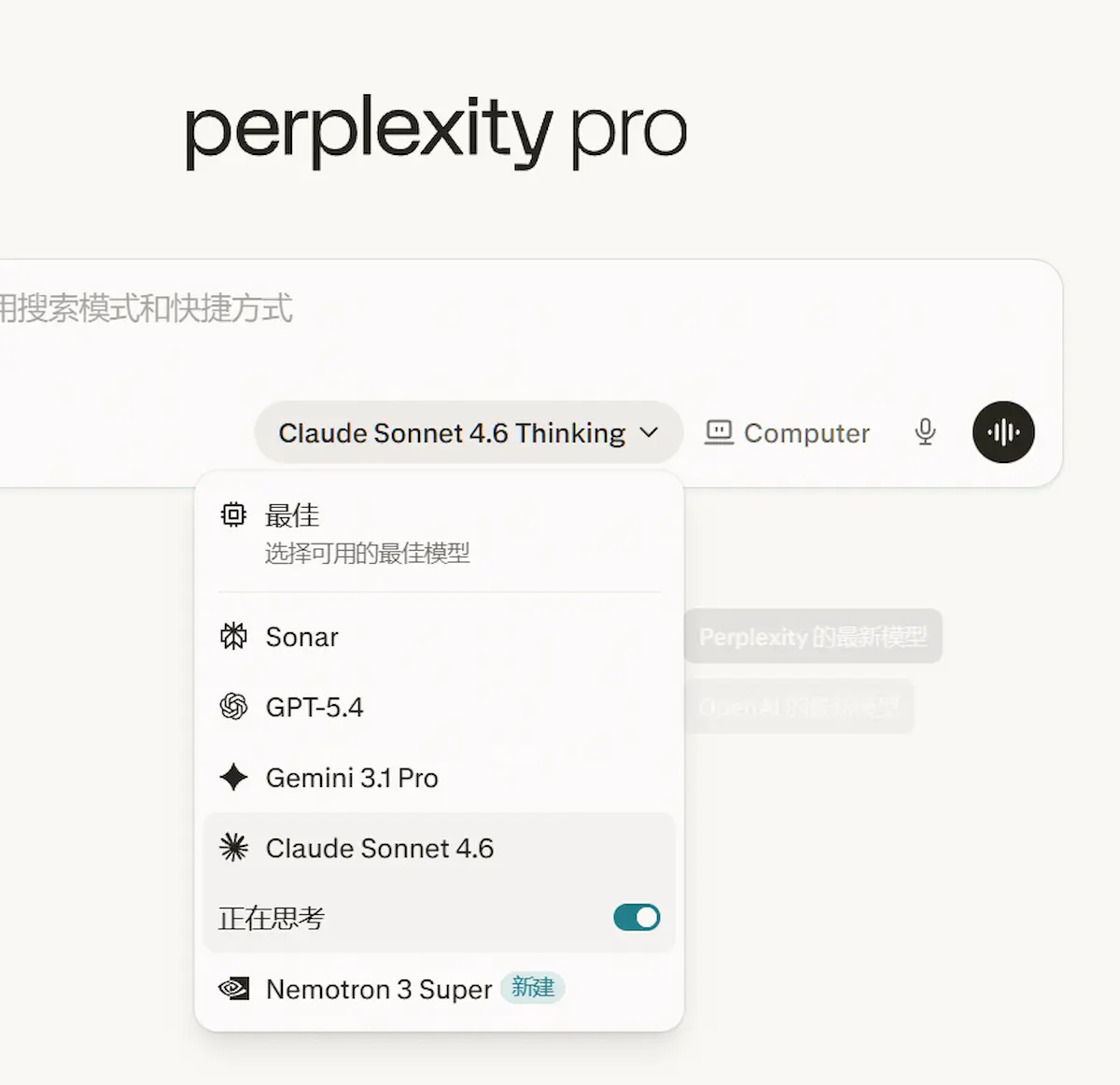
今天打开Comet,看着这六个选项,忽然想:我到底知不知道它们有什么区别?这篇文章是我把这个问题想清楚之后的记录。

最初的偷懒:一直点"最佳"
“最佳"这个选项设计得太聪明了。它会根据你的问题自动路由到合适的模型,对于大多数随手问的问题,它确实够用。但有一天我意识到,我在用一个不透明的系统做决策——我不知道它把我的问题发给了谁,也不知道为什么这个问题会发给这个模型。
当任务开始变得重要,这种模糊感就会变成一种隐患。
于是我停下来,认真看了看这六个名字。
我以为的两个误区
最开始我有一个朴素的判断:GPT 最强,选 GPT 就行。这个判断是错的。不是 GPT 最强,而是每个模型在不同场景下各有胜场。就像你不会因为"SUV 最万能"就放弃摩托车骑山路一样。
另一个误判是:名字越新越好。Nemotron 3 Super 是最新发布的(2026 年 3 月刚出),但它其实不是面向个人用户的"更强聊天模型”,而是专门为企业多 Agent 系统设计的高吞吐引擎。拿来日常聊天,大材小用。

我找到的关键证据
真正说清楚每个模型适合什么,需要看它的设计意图,而不是参数量或发布时间。
Sonar 是 Perplexity 自研模型,基于 Llama 3.3 70B,解码速度接近同类模型的 10 倍。它的设计核心就是"快"——快速事实、新闻、价格、百科。问它深度推理,不是它的强项。
GPT-5.4 是 OpenAI 第一个原生内置"电脑操控"能力的模型,支持高达 100 万 token 的上下文窗口,能直接操控浏览器和软件完成自动化任务,擅长生成幻灯片、财务模型、法律文件这类"长周期交付物"。
Gemini 3.1 Pro 是多模态底子——文本、图片、音频、视频都能处理。它能从文本直接生成可交互的 SVG 动画和实时仪表盘,在代码动画和 API 集成上有专项优化。
Claude Sonnet 4.6 引入了自适应思考(Adaptive Thinking)。它会根据问题难度动态决定思考深度:简单问题快速响应,复杂问题自动加深推理,不是固定开关。它在写作、逻辑推理和编程调试上的可信度最高——不编造,而是明确标出不确定的地方。
Nemotron 3 Super 是 NVIDIA 的 120B 参数开源模型(实际只激活 12B),混合 Mamba-Transformer-MoE 架构,推理吞吐量是同类的 5 倍。它是企业批量处理和多 Agent 并行协作的选手,不是日常聊天助手。
真正的根因
这六个模型不是"性能强弱排名",而是六种不同的工程取舍:
| 模型 | 核心取舍 | 最适合的事 |
|---|---|---|
| Sonar | 极致速度 | 快速事实 · 当日新闻 · 价格查询 |
| GPT-5.4 | 自动化 + 超长上下文 | 电脑操控 · 长文档 · 结构化交付物 |
| Gemini 3.1 Pro | 多模态理解 | 图片分析 · 代码动画 · 跨媒体任务 |
| Claude Sonnet 4.6 | 推理可信度 + 写作质量 | 写作 · 推理 · 编程调试 · 规划 |
| Nemotron 3 Super | 高吞吐 + 企业 Agent | 多 Agent 并行 · 批量处理 · 私有部署 |
| 最佳(Auto) | 透明路由 | 不确定用哪个时的默认选项 |
它们各自优化的方向不同,没有谁能替代谁。

最终修复方案:我现在的选择逻辑
梳理完之后,我的日常使用逻辑变成了这样:
Sonar — 今天的新闻、一个产品的价格、某个词条的快速核实。要的就是不等待。
GPT-5.4 — 需要打开一个网页、填一个表、生成一份完整报告的时候。或者文档超过 10 万字,需要全量读取。
Gemini 3.1 Pro — 上传一张截图要它分析、生成带动画效果的网页代码、或者需要 Google 生态深度集成的任务。
Claude Sonnet 4.6 — 写文章、写代码、做复杂推理、做策略规划。这是我用得最多的。
Nemotron 3 Super — 目前个人几乎不用。它为企业批量 Agent 任务设计,除非你在跑自动化流水线,否则没必要特意选它。
最佳(Auto) — 任务类型混杂、懒得判断的时候。不是坏选项,只是不透明。
关于那个"正在思考"的开关
模型下那个"正在思考"的切换按钮,是自适应思考——即使打开了这个开关,简单问题它也不会真的慢下来,因为它会自己判断要不要深思。
所以这个开关带来的成本其实很低。
我的结论是:默认开着就行。 唯一需要关掉的情况是你对速度极度敏感,比如在频繁刷新对话、快速迭代提示词的时候。

这次梳理最值得记住的
工具选择的困惑,很少来自工具本身太复杂。更多时候,是因为我们没有停下来问一句:这个工具是为什么场景设计的?
Perplexity 把六个来自不同厂商、不同设计取向的模型放在同一个下拉框里,方便是方便了,但也掩盖了它们之间本质上的差异。那个"最佳"按钮是一个合理的默认值,但不是一个可以完全依赖的决策者。
知道每个工具的边界在哪里,才能在它力所不及的地方及时换手。
“同频之人,终会相遇;同行之路,终有光亮。”

“技术终归是工具,而我们一次次认真把问题理顺,守住的其实不只是页面样式和代码输出,还有那一点不愿被混乱打败的心气,是每一个深夜仍愿点灯前行的人。”
「码艺轩・以技立身,实干谋生」系列 · 持续更新
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明来自:https://oklife.me。
